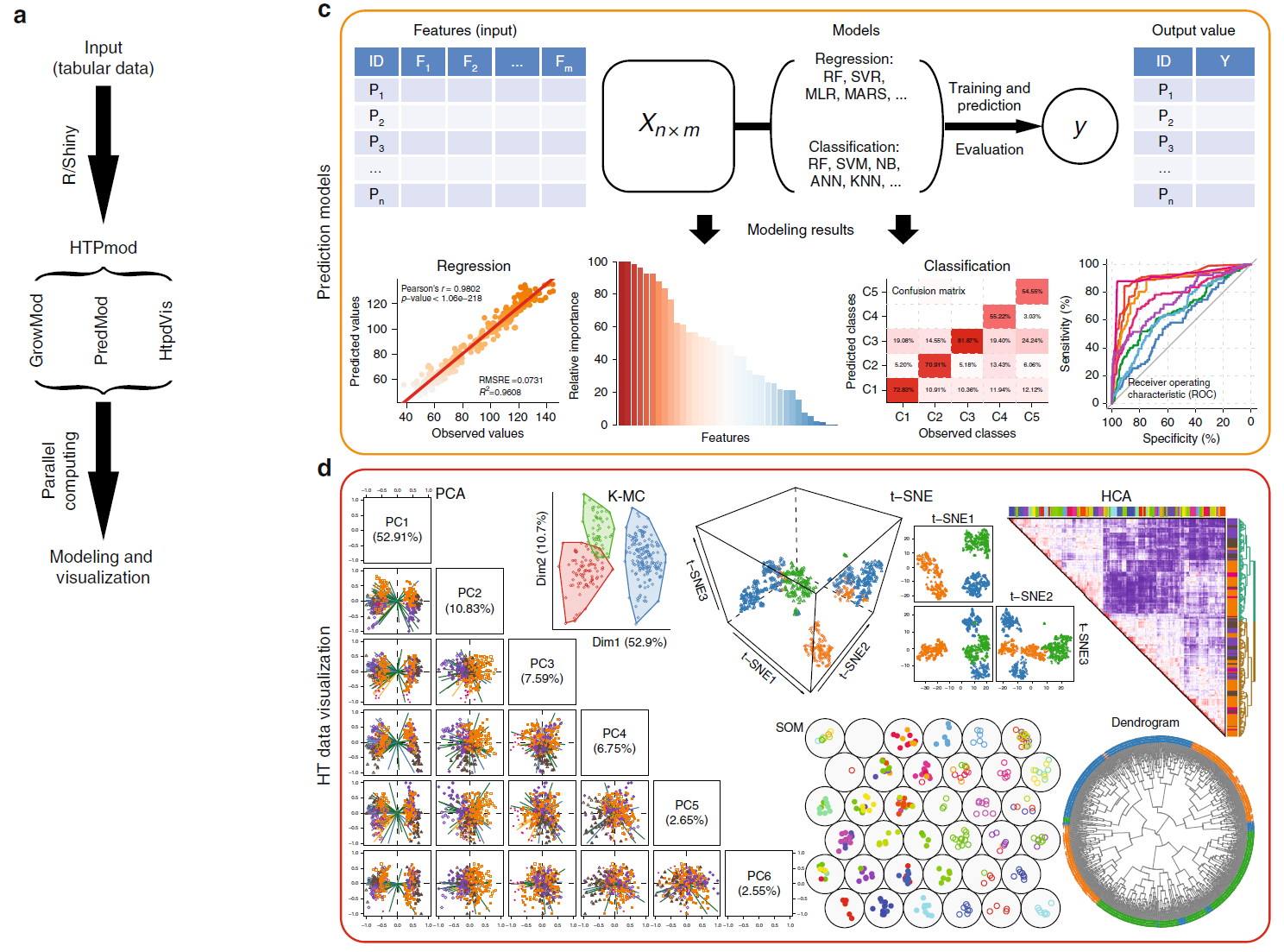
The HTPmod Shiny application enables modeling and visualization of large-scale biological data.
Chen D*, Fu LY, Hu D, Klukas C, Chen M, Kaufmann K
Commun Biol. 2018 Jul 5;1:89. doi: 10.1038/s42003-018-0091-x.
The wave of high-throughput technologies in genomics and phenomics are enabling data to be generated on an unprecedented scale and at a reasonable cost. Exploring the large-scale data sets generated by these technologies to derive biological insights requires efficient bioinformatic tools. Here we introduce an interactive, open-source web application (HTPmod) for high-throughput biological data modeling and visualization. HTPmod is implemented with the Shiny framework by integrating the computational power and professional visualization of R and including various machine-learning approaches. We demonstrate that HTPmod can be used for modeling and visualizing large-scale, high-dimensional data sets (such as multiple omics data) under a broad context. By reinvestigating example data sets from recent studies, we find not only that HTPmod can reproduce results from the original studies in a straightforward fashion and within a reasonable time, but also that novel insights may be gained from fast reinvestigation of existing data by HTPmod.